First of all, what’s really means asynchronous?
Asynchronous events are those occurring independently of the main program flow. Asynchronous actions are actions executed in a non-blocking scheme, allowing the main program flow to continue processing.
By synchronous we mean a function that calls its callback on the same tick in the javascript event loop and asynchronous is called in a different tick.
NodeJS is based in asynchronous I/O operations. This architecture schema need a way to coordinate the async actions, and for this, is used the event loop.
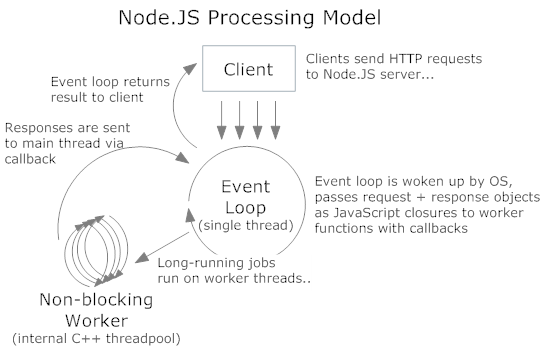
NodeJS used V8 interpreter that coverts (on the fly) JavaScript code into C++ code. In C++, for interact native threads with NodeJS events is used libuv. This is pretty awesome because you don’t need to think in threads or concurrency: Just need a provide a callback function and you callback will be caller when the operation finish. I can like see NodeJS as more high level language on the top of C++.
But, on the other hand, you can use the language in synchronous mode. It means that will block the main thread, the thread where your process is running. This is not necessary bad, but for large CPU tasks is dangerous.
Check the follow example:
// set function to be called after 1 second
setTimeout(function () {
console.log('Timeout ran at ' + new Date().toTimeString())
}, 1000)
// store the start time
var start = new Date()
console.log('Enter loop at: ' + start.toTimeString())
// run a loop for 4 seconds
var i = 0
// increment i while (current time < start time + 4000 ms)
while (new Date().getTime() < start.getTime() + 4000) { // SYNC!
i++
}
console.log('Exit loop at: ' +
new Date().toTimeString() +
'. Ran ' + i + ' iterations.')
In this case the while loop is synchronous, it is blocking the asynchronous code. The explanation about this is here:
Node cannot and will not interrupt the while loop. The event loop is only used to determine what do next when the execution of your code finishes, which in this case is after four seconds of forced waiting. If you would have a CPU-intensive task that takes four seconds to complete, then a Node server would not be able to do respond to other requests during those four seconds, since the event loop is only checked for new tasks once your code finishes.
More friendly synchronous code
If event loop works as a queue, you can put event in the queue with priority. For do it you can use process.nextTick. The definition of this method is:
process.nextTick(callback {Function})
Once the current event loop turn runs to completion, call the callback function.
Large CPU tasks normally are loops. You can convert your synchronous loops in more NodeJS friendly way:
for (var i = 0; i < 1024 * 1024; i++) {
process.nextTick(function () { Math.sqrt(i) })
}
In this way, each iteration of the loop is wrapper by process.nextTick the operation at the beginning of the next event loop iteration. Basically is wrapping your synchronous code into asynchronous and at the same time is a way to give priority to the events of the event loop.
In the NodeJS documentation about process.nextTick you can find more examples and recommendation for use it correctly:
// WARNING! DO NOT USE! BAD UNSAFE HAZARD!
function maybeSync (arg, cb) {
// this piece of code is exec synchronous.
// Notes that it follows a asynchronous interface
// (you need to provide a callback) BUT
// the operation is not deferring in the time.
if (arg) {
cb()
return
}
// this operation is definitely asynchronous.
fs.stat('file', cb)
}
In this example, maybeSync function can be a asynchronous and synchronous behaviours, depend if you provide the arg parameter. The example continues:
This API is hazardous. If you do this
maybeSync(true, function() {
foo(); // OK, the function is executed in sync mode, but how much
// time foo needs? can it block the main loop?
});
bar();
then it’s not clear whether foo() or bar() will be called first. This approach is much better:
function definitelyAsync (arg, cb) {
if (arg) {
// You want to finish this stack, but your operation
// don't need more time, so wrap it.
process.nextTick(cb)
return
}
fs.stat('file', cb)
}
Note: the nextTick queue is completely drained on each pass of the event loop before additional I/O is processed. As a result, recursively setting nextTick callbacks will block any I/O from happening, just like a while(true); loop.
Somebody can think that defer an synchronous operation that can be finish quickly is an error because you are waiting more time for resolve the operation, but this is not true because event loop is was designed for interact quickly with events, and the risk of create a sync bottleneck is higher than wait nanoseconds for the finish operation event. This don’t create a unnecessary delay in your application.
More precisely, process.nextTick defers the function until a completely new stack.
The next example is a good example about how to use process.nextTick for interleaving CPU usage and events in the event loop:
var http = require('http')
function compute () {
// performs complicated calculations continuously
// ...
process.nextTick(compute)
}
http.createServer(function (req, res) {
res.writeHead(200, { 'Content-Type': 'text/plain' })
res.end('Hello World')
}).listen(5000, '127.0.0.1')
compute()
We are enqueue a the compute function at the end of the event loop of each event loop iteration. At the same time we are dispatching other http events and all in the main node thread.
I think that in the example another important thing is present: exists a difference between a function that follow an async interface (it means, has a callback) than the function implementation need a synchronous behaviour (and block the main loop).
For example, this an example of fake async function:
function asyncFake (data, callback) {
if (data === 'foo') callback(true)
else callback(false)
}
asyncFake('bar', function (result) {
// this callback is actually called synchronously!
})
Another example:
var client = net.connect(8124, function () {
console.log('client connected')
client.write('world!\r\n')
})
In the above case, if for some reason, net.connect() were to become synchronous, the callback would be called immediately, and hence the client variable will not be initialized when the it’s accessed by the callback to write to the client!
We can correct asyncFake() to be always asynchronous this way:
function asyncReal (data, callback) {
process.nextTick(function () {
callback(data === 'foo')
})
}
BONUS: For avoid to have to write all time process.nextTick all the time you can use ensureAsync library.
What’s happens with setImmediate?
From the latest versions of node, the core of NodeJS is providing a function that is very similar to process.nextTick and is called setImmediate. The definition of the method is:
setImmediate(callback[, arg][, ...])#[link]
To schedule the "immediate" execution of callback after I/O events callbacks and before setTimeout and setInterval . Returns an immediateObject for possible use with clearImmediate(). Optionally you can also pass arguments to the callback.
Callbacks for immediates are queued in the order in which they were created. The entire callback queue is processed every event loop iteration. If you queue an immediate from inside an executing callback, that immediate won't fire until the next event loop iteration.
This is not a simple alias to setTimeout(fn, 0), it's much more efficient. It runs before any additional I/O events (including timers) fire in subsequent ticks of the event loop.
Basically is the same, but meanwhile process.nextTick put the function on the top of the next event loop iteration,
setImmediate put the function at the end of the current event loop.
Another difference is that is possible to clear the event from the event loop using clearImmediate.
About performance, I don’t feel that exists a difference between us, but setImmediate is more cross over than process.nextTick, because this depend of the process object that just exists under NodeJS (and normally in the browser you don’t handle with I/O events).
Exists a special case where setImmediate is better than process.nextTick, that is in recursive function: Under recursion using process.nextTick you have a beautiful Maximum call stack size exceeded error.
Another important point about it that I discover recently is that the interface of process.nextTick is different depend of your version of node. For example, if you see node 0.12.x documentation, the interface is simply:
process.nextTick(callback)
But if you check Node 5.x documentation, the new interface is more setImmediate like:
process.nextTick(callback[, arg][, ...])
The new interface is align with setImmediate and reduce the code necessary to pass arguments, but could breaks your old code.
Conclusions
- Don’t use it all time, just in large CPU intensive tasks (for example, in a large loop, use it in each iteration).
- Use when you aren’t sure if a function could be async or sync and you need to follow async flow. ensureAsync could be useful for this.
- Better
setImmediatethanprocess.nextTick. It is more support around node versions, browsers and is safe to use in recursion patterns. IfsetImmediatedoesn’t exist, usesetTimeout(fn, 0);fallback.
Bonus
If you package your library using browserify, process.nextTick is available in the browser as well and it is implemented as setImmediate.