URI (Uniform Resource Identifier)
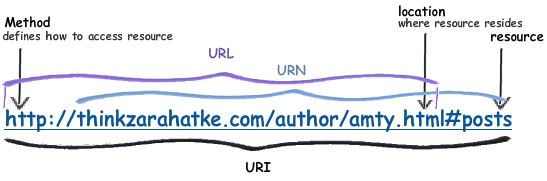
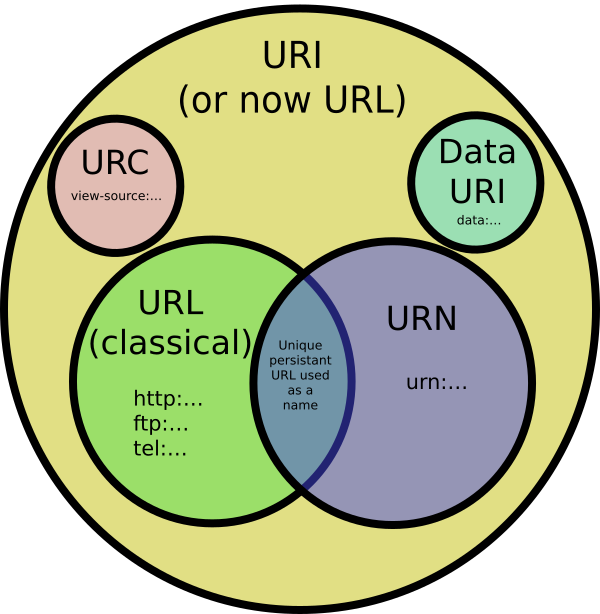
URIs are a standard for identifying documents using a short string of numbers, letters, and symbols. They are defined by RFC 3986 - Uniform Resource Identifier (URI): Generic Syntax. URLs, URNs, and URCs are all types of URI.
For example, Bitorrent files are identified by Magnet URI because the protorcol was designed for non know where is the resource.
URL (Uniform Resource Locator)
Contains information about how to fetch a resource from its location. For example:
http://example.com/mypage.htmlftp://example.com/download.zipmailto:[email protected]file:///home/user/file.txthttp://example.com/resource?foo=bar#fragment/other/link.html
URLs always start with a protocol (http) and usually contain information such as the network host name (example.com) and often a document path (/foo/mypage.html).
URLs may have query parameters and fragment identifiers.
URN (Uniform Resource Name)
Identifies a resource by a unique and persistent name, but doesn’t necessarily tell you how to locate it on the internet. It usually starts with the prefix urn. For example:
urn:isbn:0451450523to identify a book by its ISBN number.urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66a globally unique identifierurn:publishing:book- An XML namespace that identifies the document as a type of book.
URC (Uniform Resource Citation)
Points to meta data about a document rather than to the document itself. An example of a URC is one that points to the HTML source code of a page like: view-source:http://example.com/.
About W3C
The W3 spec for HTML says that the href of an anchor tag can contain a URI, not just a URL. You should be able to put in a URN such as <a href="urn:isbn:0451450523">.
Your browser would then resolve that URN to a URL and download the book for you.
The W3C realized that there is a ton of confusion about this. They issued a URI clarification document that says that it is now OK to use the terms URL and URI interchangeably (to mean URI). It is no longer useful to strictly segment URIs into different types such as URL, URN, and URC.
In addition, when you something like google.com in your browser that is not currently an URL (because URL’s need to be identified with a protocol) but the browser known how to resolve that.
Related modules I wrote
Bibliography
- @ Stackoverlfow [1] [2].
- @ Nacho Soto inception.