When you are a public service that have clients (or not necessary client, you can have users, but with clients all is more important) you need to know how the people are using the service.
On the other hand, you need to know some dev information of the service, like CPU usage, memory of the process, routes that are more slow than other,… Definetly is a useful information that you can combine with the information of your clients to know where put more effort and priorize your backlog.
Generally when you decide to exposing a public endpoint is a little complicate know the usage of your service: Maybe one day you have some request, but others day your have is less use. Of course depend of some factors and the purpose of your API and your business, but in the end of the day you want to detect usage pattern in your traffic and how the machine is supported the load.
Then, you need to monitoring.
Depend of your stack this can be more or less complicated to integrate. I have a project called zombts that use the Meteor framework. Because is a very specific environment, exist a service called Kadira that is designed specificy for recollect information from Meteor server, so the integration it’s very transparent because is very specific and offers you a good dashboard with uniform useful information (and it’s looks very nice):
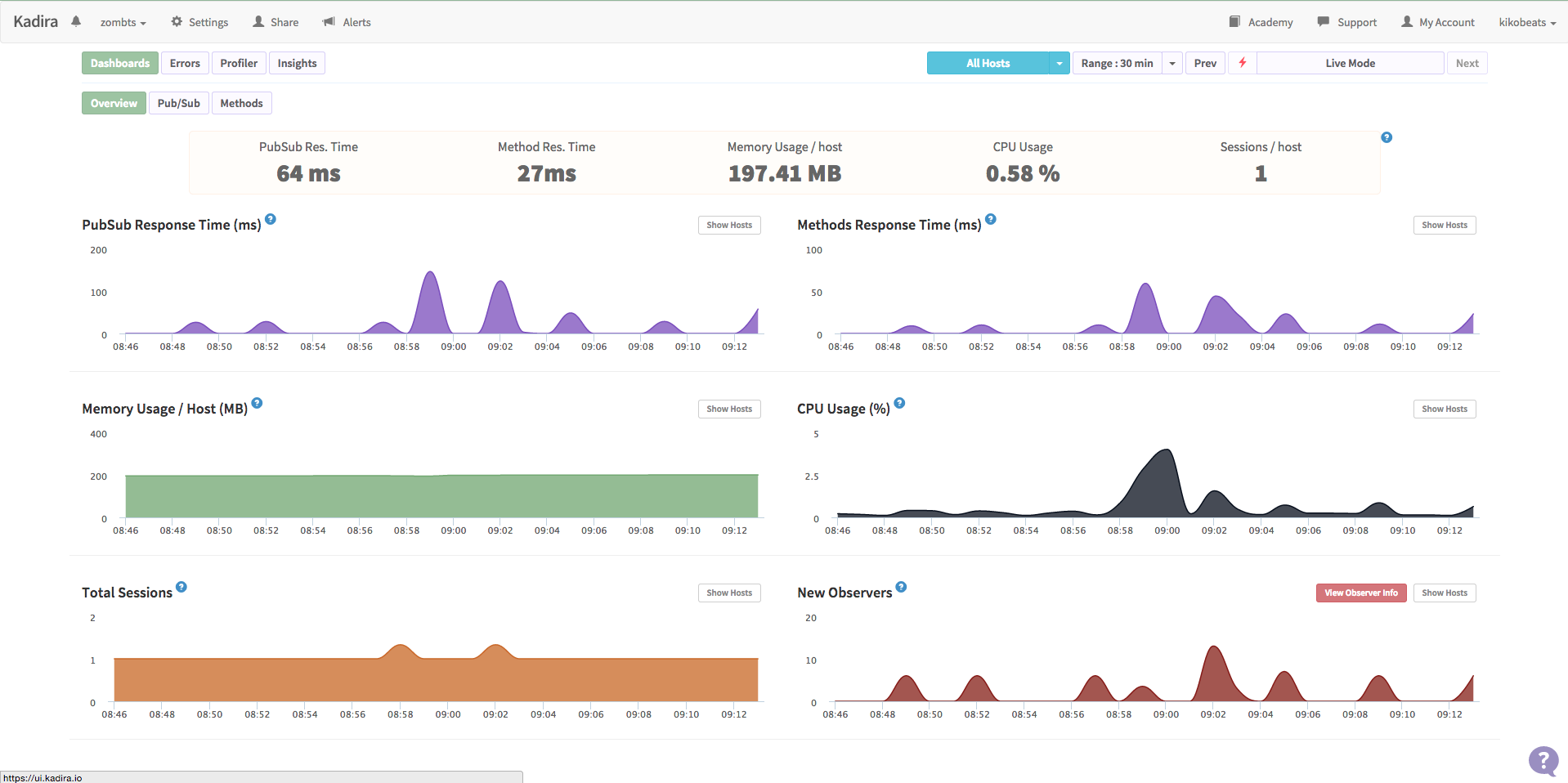
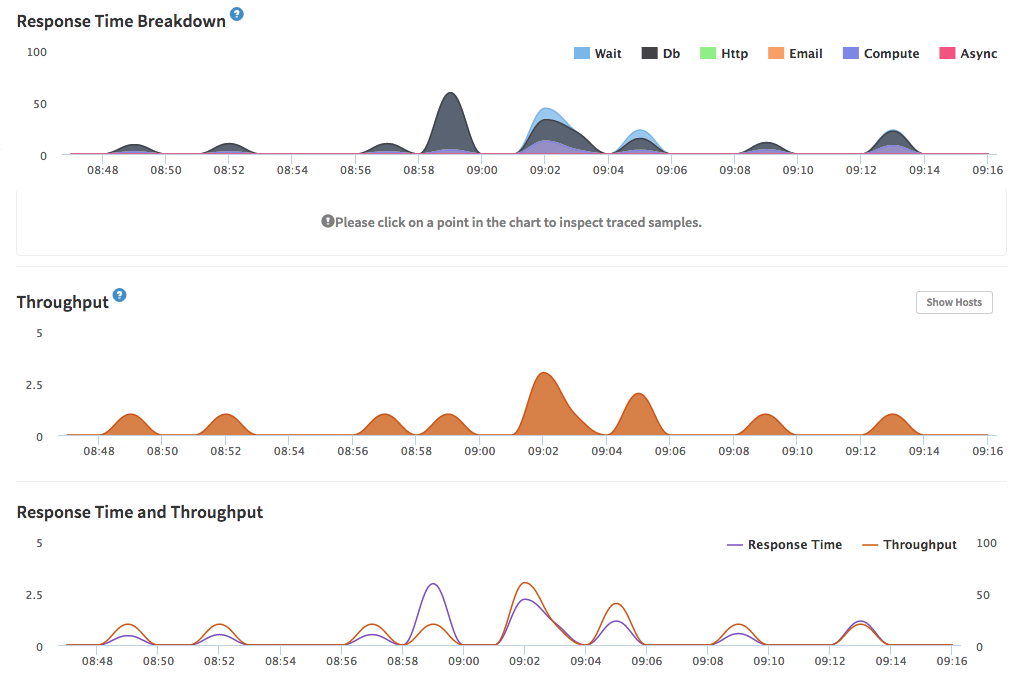
But not always is that easy.
This days in my current job I’m building a service using Sails. I’m working with Sails long time, but ever to build something big (like now) and I want to be sure that all works fine and, if I have problem, I can detect the problem quickly and fix it as soon as possible. (and always keep a public production endpoint).
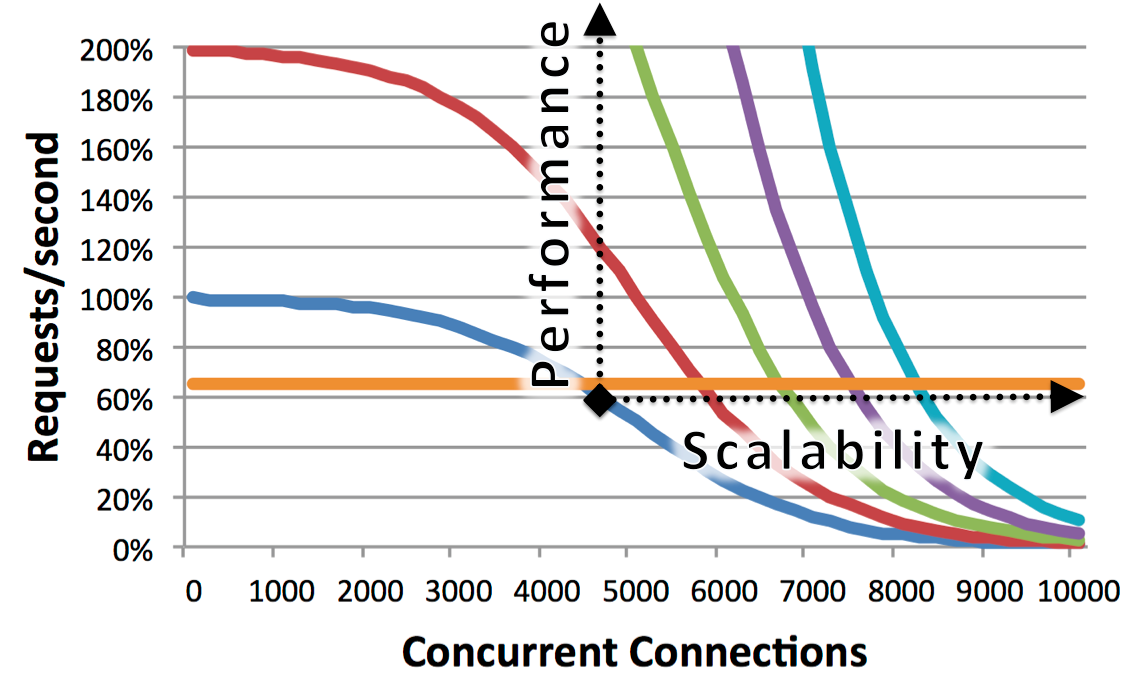
Another problem associate when you have a more big project is the scability. And this, in particular, is a little problem in NodeJS.
In theory make scalable a NodeJS should be easy, because NodeJS is single thread. For scale a project, just create a thread for each core of your machine.
A very quickly code for do it is:
var cluster = require('cluster')
var http = require('http')
var numCPUs = require('os').cpus().length
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', function (worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died')
})
} else {
// Workers can share any TCP connection
// In this case its a HTTP server
http.createServer(function (req, res) {
res.writeHead(200)
res.end('hello world\n')
}).listen(8000)
}
And that’s all. That’s all? No, not really.
In NodeJS is not possible handle with threads, just process, so if you need to share memory or coordinate the process you have problems: In NodeJS doesn’t exist the classic primitives for do this (like mutex signals). NodeJS is good in same things, but this part need more love. Maybe you aren’t interested in this aspect now, but is important know that isn’t possible.
Instead of coordinate the process in NodeJS, you can use a load balancer for coordinate the process, and maybe spawn the process on demand. I recommend visit the BalancerBattle for know real metrics about the most popular tools. But at this moment I’m not need this level of scalability, so not today.
In my personal case I used PM2. It provides me the basic as load balancer (keep the process up; have a cluster system but is beta and I checked that doens’t work very well) and make easy the integration with metrics dashboard that recently was launched, keymetrics.io
About the metrics integration part that was very simple and the result are amazing:
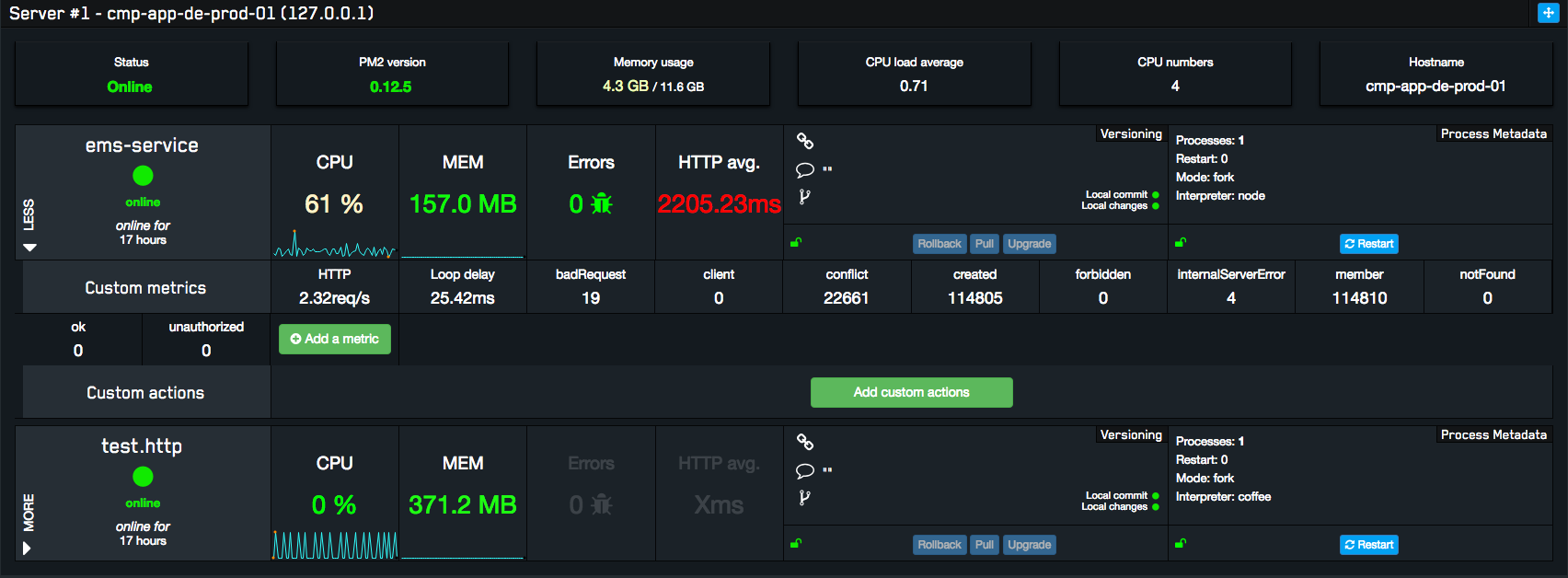
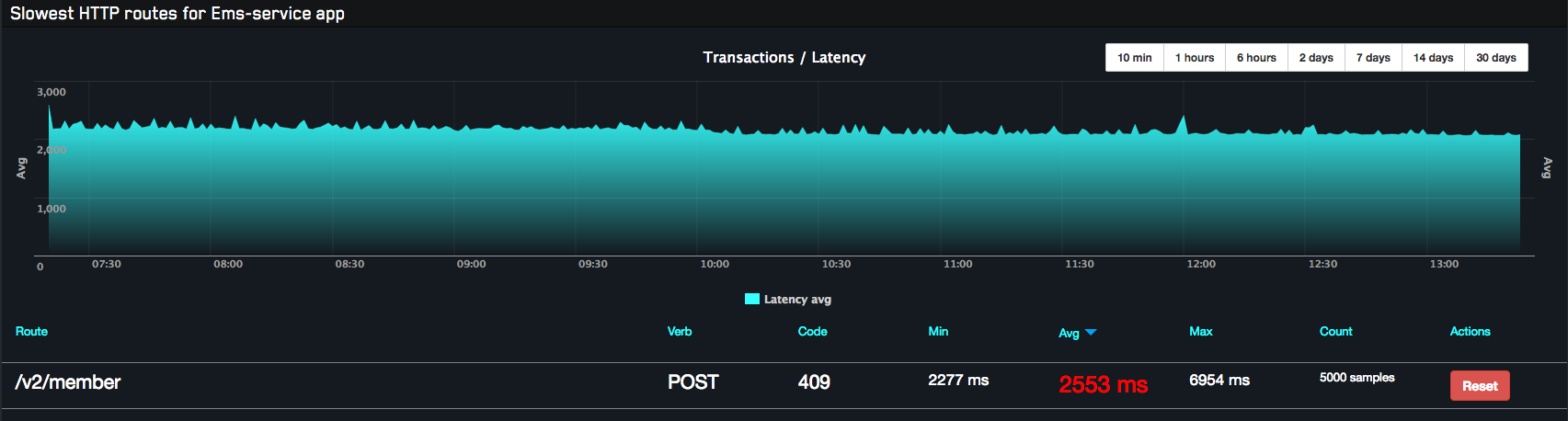
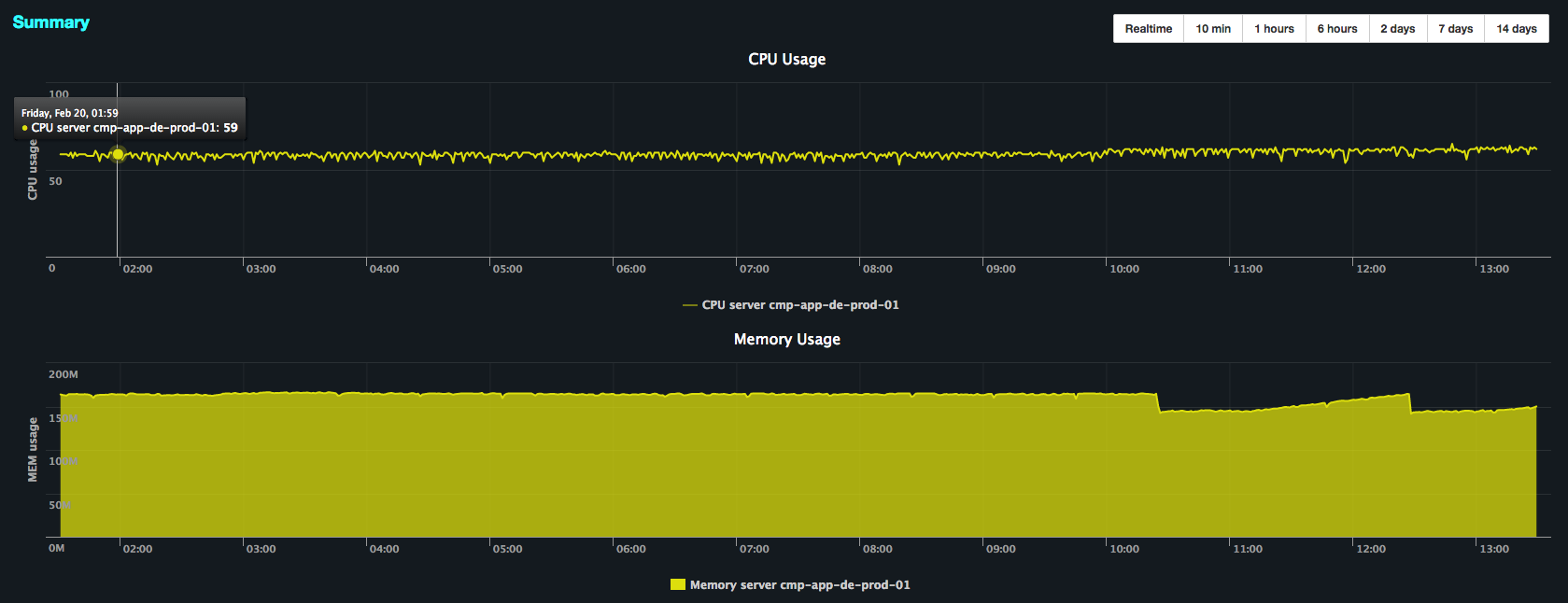
The time that I spent to setup the load balancer + metrics was ridiculous and provide me some useful information that I was looking for. Definely I love it.